


Por Inês Rocha (Jornalista), Rodrigo Machado (Ilustração e grafismo vídeo)
19 abril, 2022
- Dados da Google contam a história da nossa vida
- Gigantes tecnológicas guardam os nossos comportamentos ao pormenor
- Cartões de desconto servem para fazer perfis dos clientes
- O labirinto dos "Data Brokers"
- Que dados recolhem as "cookies" no nosso "browser" ?
- Telemarketing: como descobrem o nosso número de telefone?
Sou mulher, tenho entre 25 e 34 anos, não tenho filhos, sou casada, vivo no Porto, tenho um bacharelato, sou inquilina e funcionária de uma empresa de grande porte.
Se tivesse de confiar nas inferências que a Google faz da minha atividade online para me apresentar aos leitores, não estaria muito longe da realidade. Não sou casada mas vivo em união de facto; fui inquilina nos últimos oito anos; sou licenciada (bacharelato na tradução direta do inglês); tenho 30 anos e trabalho no grupo Renascença Multimédia, atualmente com 255 funcionários - por isso, considerada uma grande empresa.
Todos sabemos que a nossa atividade online é seguida por um sem número de empresas, muitas das vezes cujo nome nunca ouvimos falar. Mas ver, ao pormenor, tudo o que cada uma delas sabe e o que adivinha sobre nós é um exercício, por vezes, assustador.
Em 2015, uma investigação da Universidade de Stanford e de Cambridge demonstrou que bastavam 10 “likes” a um computador para conseguir prever melhor a personalidade de um indivíduo do que um colega de trabalho; para ultrapassar um amigo, precisava de 70 “likes”; para conhecer alguém melhor do que a família, bastavam 150 “likes”; o modelo precisava de apenas 300 “likes” para prever melhor a personalidade da pessoa do que o próprio cônjuge.
No último ano, no âmbito de uma investigação Renascença, pedi a cerca de 70 empresas que me dissessem que dados meus guardam e como os tratam.
Quando pedi os meus dados ao Facebook, não esperava ver que tem uma lista de 4.952 likes meus, 4.546 pesquisas (só nos últimos quatro anos) e registos da minha atividade em 1.624 sites fora do Facebook, incluindo as datas e horas a que os visitei. Tinha guardadas todas as conversas que tive no Messenger desde de que aderi à rede social, com 656 pessoas, e uma lista de todos os pedidos de amizade que recebi e enviei nos últimos nove anos, incluindo os que rejeitei ou removi.
Tinha também uma lista de todas as minhas entradas na aplicação desde 2019, incluindo data, hora, IP do dispositivo que usei e localização do mesmo. Através desta localização, consegui ver distintamente quando andei a cobrir a campanha eleitoral, pelo país, nas Legislativas de 2019; quando me mudei de Lisboa para o Porto e quando fui morar para Vila Nova de Gaia.
Dos dados que descarreguei da rede social, descobri ainda que mais de 30 anunciantes partilharam os meus contactos com o Facebook, para me dirigirem anúncios diretamente, dentro da rede social.

Dados da Google contam a história da nossa vida
Mas nada bate a Google no volume de dados que guarda sobre mim. Quando pedi todos os meus dados à gigante norte-americana, através do “Google Takeout”, fiquei surpreendida com a quantidade de dados que tinha para descarregar: 63 GB de dados.
Esta lista inclui todos os dados incluídos na conta Google - incluindo o e-mail, os ficheiros do Google Drive, do Google Fotos e os vídeos que publicamos no Youtube.
Ainda assim, se excluirmos estes ficheiros mais pesados que voluntariamente guardamos nos servidores da Google, sobra ainda muita informação - no meu caso, eram 328 “megabytes” de ficheiros.
A pasta mais interessante de analisar é a “Minha Atividade” - onde se inclui o histórico de pesquisas que fazemos no motor de busca da Google, tanto escritas como por imagens, e a lista de sites visitados através do Google. Inclui também as pesquisas do Youtube e no Google Maps, uma lista de todos os anúncios em que clicámos, entre outros dados recolhidos noutras aplicações.
O histórico de pesquisas é, basicamente, um resumo fiel da nossa vida, das preocupações, dos anseios, dos desejos, das dúvidas - no meu caso, também de todas as reportagens que fiz.
Olhando para aquela lista de 114.916 pesquisas por palavras e 6.493 por imagens, consigo viajar no tempo e identificar os momentos em que estava a decidir que curso tirar; as inquietações dos tempos de faculdade; a vida em Erasmus; quando estava à procura do primeiro emprego; à procura de casa; quando realmente mudei de morada; quando comprei carro; as fases em que dediquei mais tempo à música; em que estive a preparar as minhas viagens; em que me entusiasmei com pratos italianos ou asiáticos; em que decidi aprender sobre os mercados e quando mergulhei em todos os pormenores das leis de proteção de dados. Identifiquei também a banda sonora de grande parte dessas fases.
Apesar de tudo, a base de dados da minha vida não está completa - em 2018, quando o RGPD entrou em vigor, fiz este trabalho - o que me fez ler com atenção a nova política de privacidade da Google e recusar que guardasse as minhas pesquisas.
A recolha voltou em agosto deste ano, quando mudei de iPhone para Android - em algum momento que me passou despercebido, aceitei de novo que a Google guardasse toda a minha atividade online, até dezembro, quando fiz “download” dos meus dados e me apercebi do erro.
Ainda assim, com os dados que a Google tinha sobre mim consegui chegar a estatísticas muito interessantes sobre a minha vida (e lembrar-me de micro-histórias que marcaram os meus últimos anos).
Como a frequência com que uso as pesquisas da Google: ao longo dos anos, nota-se uma tendência de forte crescimento no número de pesquisas, em particular a partir de 2016.
Em janeiro de 2016, pesquisei mais do que no resto do ano inteiro e muito mais do que a média dos anos anteriores. Um dado que conta uma fase da minha vida: estava a preparar um InterRail, que faria no mês seguinte, numa altura em que o “roaming” ainda não era gratuito na União Europeia - o que implicou planeamento ao pormenor, antes de partir.
Veja também

Quis saber se o RGPD funciona. Então, fiz “download” da minha vida

Sites públicos ajudam a construir perfis para nos adaptar publicidade

Como se faz um pedido de acesso a dados?

O que podemos fazer para reduzir a nossa Pegada Digital?
Mas a recolha começou bem mais cedo, ainda estava no secundário, pesquisava artistas como Avril Lavigne e estavam na moda os “Fotologs”. Pelas minhas pesquisas, é possivel também perceber algumas inquietações a nível espiritual, nesta fase.
Em 2012, os meus hábitos de pesquisa foram muito mais intensos do que nos restantes anos - estava a acabar o curso e comecei a busca pelo primeiro emprego, numa altura em que o desemprego era a norma. Está lá também a vontade de emigrar e como isso não aconteceu por pouco. Em agosto, fui em missão a Angola, onde não tinha praticamente acesso à internet - por isso o número tão baixo de pesquisas nesse mês.
Janeiro de 2017 foi o mês em que mais recorri ao Google, dos anos analisados. Nesta altura, pesquisei demasiado sobre Donald Trump e o hino dos EUA, para fazer este vídeo e sobre Obama, para fazer este.
As pesquisas do início de 2018 mostram bem porque decidi impedir a Google de recolher mais dados de pesquisa: Facebook, Zuckerberg, dados, data, GDPR, RGPD são algumas das palavras mais pesquisadas.
Foi também nesta altura que fiz um trabalho sobre o sistema de crédito social na China - que mostra como é a vida num mundo sem privacidade conjugado com um sistema autoritário. Por isso “China” e “credit” são palavras muito pesquisadas.
E, em minha defesa, as referências a canábis serviram exclusivamente para fazer este trabalho.
Na base de dados de pesquisas guardada pela Google consigo também identificar informações sensíveis e momentos de vulnerabilidade que, conscientemente, não partilharia com mais ninguém - muito menos com uma empresa do outro lado do oceano que pretende lucrar com a minha informação pessoal.
Se a recolha de dados não tivesse parado em 2018, quando optei por impedir a Google de guardar dados, provavelmente veríamos um crescimento cada vez mais acentuado no número de pesquisas com o passar dos anos - e a Google teria uma imagem muito mais completa sobre a minha vida.

Não foram apenas os meus hábitos que mudaram em relação às pesquisas na Google: este crescimento está em linha com o crescimento do volume de dados criado, anualmente, a nível mundial - nos últimos anos, a produção de dados cresceu mesmo de forma exponencial.
Um artigo publicado em fevereiro de 2021 por investigadores da Universidade de Pristina, no Kosovo, mostra que, a cada segundo, são produzidos 1.7 megabytes (MB) de informação por pessoa. Segundo previsões do International Data Group, uma empresa norte-americana de pesquisa, o crescimento no volume de dados entre 2020 e 2025 será exponencial, passando de 44 para 163 zettabytes (algo como 163 mil milhões de terabytes) por ano.
Gigantes tecnológicas guardam os nossos comportamentos ao pormenor
O nível de detalhe dos dados que as grandes empresas tecnológicas guardam sobre nós é simultaneamente previsível e fascinante de observar.
Se os conteúdos que as aplicações nos sugerem parecem muitas vezes autêntica magia, ver a quantidade de dados de que estas empresas dispõem sobre os nossos hábitos e gostos retira completamente a magia ao processo.
Quando descarregamos os nossos dados da Netflix, por exemplo, somos brindados com listas de todas as pesquisas e todos os cliques feitos por todos os perfis da conta que assinamos. Temos ainda uma lista de todos os vídeos vistos com aquela assinatura - no meu caso, que partilho conta, eram 6.711 vídeos, registados com data e hora, se foi "autoplay" ou com clique do utilizador , em que aparelho foi visto e quanto tempo visualizado. É com base nestes dados que a plataforma infere os gostos do utilizador e sugere conteúdos semelhantes.
O Facebook regista todos os vídeos vistos, tempo de visualização e em que segundo parei de os ver. Regista também os artigos que li, publicações e anúncios que me passaram à frente dos olhos.
O Spotify guarda registos de todas as pesquisas e todas as faixas ouvidas, através das quais infere os meus interesses. A empresa encaixa-me no perfil de ouvinte de podcasts, apreciadora de “true crime”, e acha que tenho interesse em negócios, comédia, cultura e sociedade, entre outros. Em grande parte dos casos, são inferências bem certeiras. Sabe também que tenho um carro Renault - já que às vezes ouço música ou podcasts no carro - e que tenho um Chromecast, um aparelho para fazer "streaming" de conteúdos noutros dispositivos.
A Amazon mostrou-me uma lista de 33 anunciantes em cujos anúncios aparentemente cliquei. Com base nesses cliques, associou o meu perfil a diferentes categorias, como “livros e revistas”, “casa e jardim”, “diversão e hobbies” e “entretenimento vídeo”. Como seria de esperar, tinha também uma lista de todos os produtos clicados, adicionados ao carrinho e comprados.
Já a Uber tinha registo de todas as 66 viagens ou encomendas feitas desde que instalei a app, com moradas completas do local de partida e chegada, hora de chamada, hora de fim de viagem, quilómetros percorridos e preço da viagem. Tem também as minhas últimas moradas, informações sobre os meus dispositivos e todos os métodos de pagamento já registados.
O Instagram, além de guardar toda a minha atividade online e de “ler” as mensagens que troco, tem uma “coleção de sentimentos” retirada do conteúdo que vejo nos Reels. “Adorável”, “emocional”, “fascinante”, “divertido”, mas também “ridículo” e “relaxante” são alguns dos sentimentos registados.
Há também um conjunto de tópicos que a rede social associou a mim, com base na minha navegação, muitos deles bem próximos dos meus gostos. “Fotografia de Viagem”, “jornais e revistas”, “viagem e turismo Itália”, “MPB (música)” mas também alguns mais aleatórios, como “macacos” (não tenho um interesse particular) e “novelas” (não vejo).
Mas algo que nenhuma destas empresas fornece ao utilizador, quando pede os seus dados, é um vislumbre sobre qual a lógica por detrás dos seus algoritmos de recomendação de conteúdos. Nesse aspeto, não há controlo por parte do utilizador, nem sobre o nível de dados recolhido nem sobre a forma como são utilizados - a única opção, caso se queira opor aos tratamentos automatizados (um direito previsto no Regulamento Geral de Proteção de Dados), é mesmo deixar de usar aqueles serviços.
Cartões de desconto servem para elaborar perfis dos clientes. Mas não sabemos como
 Continente e Pingo Doce assumem que fazem perfis automatizados com base nos dados dos clientes dos cartões de desconto. Ilustração: Rodrigo Machado/RR
Continente e Pingo Doce assumem que fazem perfis automatizados com base nos dados dos clientes dos cartões de desconto. Ilustração: Rodrigo Machado/RR
Nos pedidos de acesso que fiz a 72 empresas, incluí os dois maiores operadores do retalho alimentar em Portugal - Continente e Pingo Doce. Incluí também uma loja de roupa – Springfield, detida pela espanhola Tendam.
Quando pedi os meus dados ao Continente, recebi respostas de duas entidades diferentes: do próprio Continente e do Cartão Continente. Segundo aquela cadeia de hipermercados, “por questões de segurança e privacidade da informação, a base de dados do Cartão Continente é diferente da base de dados do Continente Online”.
O Cartão Continente, o cartão de fidelização do supermercado da Sonae MC, é utilizado por uma grande percentagem da população portuguesa. Segundo dados divulgados pela empresa, em 2021, quatro milhões de portugueses usaram o cartão de descontos.
O Continente diz ter apenas os dados que eu própria forneci - nome, e-mail, telefone, NIF e número do Cartão Continente. Já o Cartão Continente tem mais alguns dados: morada completa, data de nascimento, género, número de pessoas do agregado familiar, documento de identificação e dados de faturação.
O Continente diz não haver lugar a perfis automatizados no tratamento de dados. Já o Cartão Continente diz que os dados de consumo registados no cartão “são utilizados para o desenvolvimento, gestão e comunicação de ofertas gerais e de ofertas personalizadas de produtos, bens e serviços ajustadas aos seus interesses. Os perfis são evolutivos e baseados no histórico de transações, sendo que nenhum perfil é criado exclusivamente com base em decisões automatizadas”.
Não tive mais explicações sobre os perfis associados à minha conta. Para procurar perceber melhor como funcionam os tratamentos de dados do Cartão Continente, pedi à Sonae MC - agora enquanto jornalista - para fazer uma reportagem sobre o assunto. O pedido foi recusado.
O Cartão Poupa Mais, do Pingo Doce, guarda dados como nome, morada, género, data de nascimento, número de telemóvel e documento de identificação, além do histórico de compras associado.
A empresa não respondeu, no e-mail, se faz perfis automatizados com base nos dados dos clientes, mas a política de privacidade do cartão é clara: a empresa recolhe dados “de perfil e localização, com base nos quais o Pingo Doce e a BP Portugal [empresa petrolífera associada a este cartão] poderão elaborar perfis destinados a possibilitar o desenho de campanhas e cupões promocionais ajustados aos interesses e preferências dos titulares do Cartão Poupa Mais”.
A espanhola Tendam, proprietária de lojas como Springfield, Cortefiel, Pedro del Hierro e Women’s Secret, assume também que o cartão de cliente serve para tratar dados “não fornecidos conscientemente pelo utilizador, resultantes da aplicação de algoritmos (dados inferidos)”. O objetivo é “conhecer os interesses, as preferências sobre os produtos e lojas, para traçar um perfil das pessoas”.
“Eu não tenho coisas grátis porque não gosto de pagar com a minha pessoa”
Sobre a construção de perfis de clientes feita por grandes estabelecimentos comerciais em troca de descontos, sem mencionar casos concretos, Luís Antunes, diretor do Centro de Competências em Cibersegurança e Privacidade da Universidade do Porto, admite que “muitas pessoas afirmam que, a troco de um desconto numa superfície comercial, estão disponíveis para permitir alguns ‘insights’. Uma coisa que eu não farei. Eu não tenho coisas grátis porque não gosto de pagar com a minha pessoa”, diz.
O professor da Universidade do Porto dá um exemplo: “se eu consumir um quilo de arroz de dois em dois meses, recebo, 15 dias antes, um vale de desconto para arroz para me fidelizar. Até aqui, os meus amigos dizem ‘porreiro’”.
“Mas se eu comprar os meus contracetivos numa destas superfícies comerciais, nunca nenhum amigo meu me disse que recebeu um vale desconto para comprar os contracetivos. E porquê? Porque estas superfícies não querem dar a entender ao comum cidadão o quão intrusivas conseguem ser na nossa privacidade, e dizer ‘eu sei que consomes uma caixa dois em dois meses, portanto pega lá um vale, senão daqui a nove meses eu vou-te mandar é puericultura’”.
“Do ponto de vista tecnológico, um quilo de arroz ou uma caixa de preservativos é igual, é um objeto que tem um padrão de consumo”, lembra o professor.
“Neste aspeto, a tecnologia é agnóstica. Mas o grau de intrusão na nossa intimidade ficaria a nu se me mandassem um vale de contracetivos”, sublinha.
Procurei saber o que os “data brokers” sabem sobre mim. A maior parte das vezes, entrei num labirinto
Um dos objetivos desta investigação era utilizar o meu direito de acesso para descobrir o que os “data brokers” - em português “corretoras de dados” - e empresas de publicidade sabem sobre mim.
O que são “data brokers”? São empresas que recolhem informação de utilizadores online para a vender a outras empresas. A forma mais comum de recolha é através de "cookies", pequenos ficheiros que ficam guardados no "browser" quando entramos em determinado site e seguem o utilizador pela web, registando os seus hábitos e gostos. Mas há outras formas de rastrear a navegação, com códigos embebidos em aplicações ou no "browser", para identificar o utilizador com base no dispositivo (“browser fingerprinting”).
Estes dados são normalmente pseudonomizados - estas empresas não sabem o nosso nome. No entanto, existe sempre o risco, com suficiente cruzamento de dados, de ser possível identificar determinada pessoa.
Procurei então fazer pedidos de acesso aos “data brokers” mais conhecidos do meio - Acxiom, Experian, Equifax, Oracle, Eyeota.
Pedi ainda os meus dados à Criteo, criadora da plataforma de publicidade líder do mercado “AdTech”, e ao Nónio, uma plataforma portuguesa criada pelos maiores grupos de comunicação do país, incluindo o Grupo Renascença.
A Acxiom e a Experian dizem não ter dados de residentes em Portugal.
A Equifax dificulta bastante o processo de acesso a dados. A agência de monitorização de crédito tem uma página onde é possível fazer pedidos de acesso, mas para o fazer é preciso criar uma conta no site, onde pede nome, data de nascimento, e-mail, morada e moradas anteriores. Optei por não o preencher. Enviei também um pedido para a Equifax Portugal, que está sob a alçada da Equifax Espanha, mas não recebi resposta.
A Oracle responde a pedidos de acesso com uma mensagem automática, a dirigir o utilizador para uma página onde terá mais indicações sobre como fazer pedidos de acesso. Nessa página, tem uma lista de 14 serviços da empresa, onde o utilizador deve fazer "login", individualmente, para poder fazer um pedido.
A empresa dá ainda ao utilizador a possibilidade de ver as informações que a empresa guarda sobre si através de"cookies" registados no seu dispositivo. Para isso, é preciso descarregar um documento na página do “Oracle Data Cloud Registry”, que supostamente indica “os tipos de segmentos de interesse de terceiros que são partilhados ou vendidos aos clientes do Oracle Data Cloud”.
No entanto, os segmentos que aparecem neste documento não são enquadrados ou explicados - fica pouco percetível para o utilizador o significado daquela informação.
Que dados recolhem as "cookies" no nosso browser?
Dos "data brokers" e plataformas de publicidade que questionei, recebi os meus dados de três entidades: Eyeota, Criteo e Nónio.
Eyeota e Criteo recolhem dados através de "cookies" - dados esses que são pseudonomizados. Por isso, para dar seguimento ao pedido de acesso, dão instruções ao utilizador para que envie o ID das cookies que tiver registado nos "browsers" dos seus equipamentos - e o ID de publicidade do "smartphone" , no caso da Eyeota.
Com esse conjunto de letras e números, as empresas conseguem procurar nos seus sistemas e partilhar todas as informações registadas sobre o utilizador.
No caso da Criteo, recebi uma base de dados com três páginas: uma referente aos dados recolhidos nos sites dos seus clientes anunciantes; outra com dados referentes aos anúncios mostrados pela Criteo nos seus parceiros “publishers”; outra com informação sobre anúncios em que eu tenha clicado.
No primeiro caso, tinha 228 linhas de dados recolhidos da minha navegação nos sites Imovirtual, Idealista e Fnac - sites que utilizam os serviços da Criteo para adaptar os seus anúncios. Noutra página, tinha uma lista de 28 artigos que li, em diferentes sites de notícias, onde me foram mostrados anúncios servidos pela Criteo - anúncios da Fnac, da Idealista, da Worten, da Pixartprinting, da La Redoute e da Joom Portugal.
As cookies da Criteo guardam informações sobre qual o meu "browser", o meu sistema operativo, os timestamps das navegações, entre outros. Dizem não cruzar esses dados com outros dados identificáveis.
No caso da Eyeota, uma empresa com sede em Singapura que faz perfis de utilizadores com base na sua navegação, recebi dois documentos: um com dados recolhidos no próprio site da Eyeota, outro com dados recolhidos pelo "cookie" da empresa, anonimizados, que incluem endereço IP, ID associado à "cookie" ou ao dispositivo móvel, endereço de e-mail encriptado, data e hora, URLs, sistema operativo e versão do browser.
Neste último pedido que fiz, a Eyeota não tinha muita informação sobre mim. No entanto, em 2018 fiz o mesmo pedido à mesma empresa. Na altura, enviei o ID de três "cookies" que tinha guardadas no "browser''. No total, com base na minha navegação, tinha sido associada a 1.122 segmentos de perfis para me adaptar publicidade, como “artes e entretenimento”, “saúde e fitness” ou “notícias de tecnologia”.
O Nónio tem acesso aos dados que forneci no registo: nome, data de nascimento, género, país e e-mail.
A plataforma diz criar perfis para “prestar um serviço personalizado na apresentação de notícias, consoante as suas preferências”.
Estes perfis são anonimizados e, para a sua construção, são utilizadas apenas duas categorias de dados: idade e género. São também estes dados que são partilhados com o fornecedor de DMP (Plataforma de Gestão de Dados), para dirigir publicidade personalizada ao utilizador.
Para isso, a plataforma “recolhe informações técnicas do dispositivo do utilizador sempre que este visita os websites”. As informações são obtidas através do “browser” e dizem respeito ao “endereço IP, sistema operativo e motor de busca da Internet utilizados, resolução do ecrã e websites de referência”.

Como é que as empresas descobrem o nosso número de telefone? Cuidado com os inquéritos e os prémios fáceis
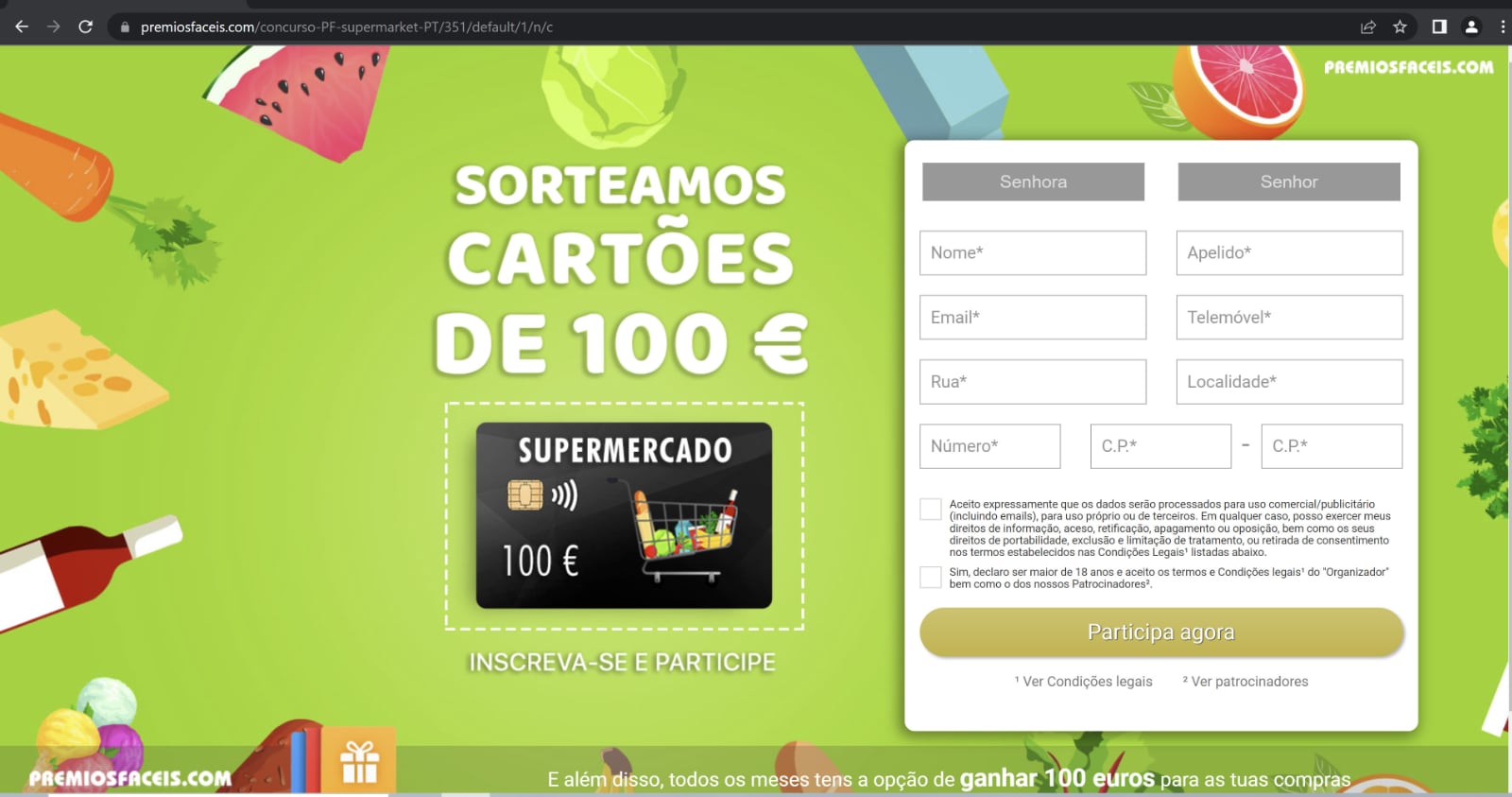 É através de passatempos como este que empresas de Telemarketing têm acesso a listas de contactos, para venderem os seus produtos. Como se pode ver na imagem, está explícito que o utilizador aceita o uso dos seus dados para uso comercial/publicitário, para uso próprio ou de terceiros. Em muitos casos, os avisos estão muito mais escondidos.
É através de passatempos como este que empresas de Telemarketing têm acesso a listas de contactos, para venderem os seus produtos. Como se pode ver na imagem, está explícito que o utilizador aceita o uso dos seus dados para uso comercial/publicitário, para uso próprio ou de terceiros. Em muitos casos, os avisos estão muito mais escondidos.
Além dos “data brokers” que vivem de classificar os nossos hábitos online para nos dirigirem publicidade, existem também “data brokers” que recolhem dados pessoais, em particular de contacto, para poderem vender a empresas que fazem marketing direto.
Como é que as marcas descobrem o nosso número de telefone, o nosso nome e às vezes mais informações pessoais que nunca partilhamos com elas?
Foi isso que tentei descobrir em 2018, quando o RGPD começou a ser aplicado. Fiz um pedido de acesso a dados à Medicare, marca que me ligava constantemente, apesar dos meus pedidos para que apagassem os dados.
A marca respondeu que trabalha com parceiros terceiros para promover os seus produtos. No meu caso, tinha sido o parceiro Teleperformance a ter acesso aos meus dados pessoais através de um questionário que terei preenchido, para participar num sorteio. Esse sorteio, “Prémios Fáceis”, era gerido por uma empresa alemã, “HelloMail Interactive GmbH”. Nos termos e condições, que o utilizador tinha de aceitar, era explícito que os dados seriam processados para fins de marketing, para uso próprio ou de terceiros.
A Medicare garantiu que deu ordens à Teleperformance para eliminar os meus dados e, a partir daí, deixei de receber telefonemas em nome da empresa.
Neste trabalho, optei por fazer um pedido de acesso à Teleperformance, para verificar se os meus contactos foram efetivamente apagados do sistema. Em resposta, a empresa garantiu não ter qualquer dado meu. Fiz também um pedido à empresa alemã, que nunca respondeu.
Hoje, o site Prémios Fáceis é gerido por uma empresa espanhola, Webpilots España, SL. Fiz um pedido de acesso a esta empresa, mas também não recebi resposta.
Quis descobrir como a Wizink teve acesso aos meus dados. A empresa dificultou o processo ao máximo
Outra das empresas contactadas nesta investigação foi a Wizink, instituição de crédito espanhola que durante alguns meses me ligava frequentemente para tentar vender o seu produto.
O processo começou por ser dificultado: mesmo para quem não é cliente deste banco digital, quem quer fazer um pedido de acesso é obrigado a comprovar a sua identidade enviando uma cópia do cartão de cidadão ou preenchendo um documento a recusar a reprodução do cartão - mas com outros dados pessoais, como nome completo, data de nascimento, número do cartão de cidadão, validade e NIF.
Depois de enviar o documento, já que era a única maneira de avançar com o pedido, recebi esta resposta: “não encontrámos, no nosso sistema, qualquer dado pessoal seu”.
Só quando perguntei quais os parceiros da empresa na área do telemarketing, fui informada que o banco “trabalha com intermediários que adquirem bases de dados” e que deveria exercer os meus direitos junto da Transcom, uma agência alemã que se descreve como um “fornecedor global de serviços na área de Contact Center e especialista em apoio ao cliente”.
Fiz então um pedido de acesso a dados à Transcom, que disse ter reunido todos os meus dados e enviado de volta à Wizink, já que é o banco o “controlador” dos dados neste processo - o que significa que deveria ter sido o Wizink a tratar de todo o processo. Até à data de publicação deste artigo, a Wizink não me enviou os dados fornecidos pela Transcom.
Mas este não é o único parceiro do banco na área do Telemarketing. Outro dos parceiros conhecidos é a Content Ignition, um “data broker” português que trabalha também com a Endesa, o Bankinter, a EDP, o Fitness Hut, a Nowo, a Iberdrola, entre muitas outras marcas conhecidas por optar pelo marketing direto.
Antes de a Wizink me encaminhar para a Transcom, optei por fazer um pedido de acesso à Content Ignition. No site, a empresa descreve-se como criadora de “oportunidade de contacto entre os nossos clientes e milhões de utilizadores online”. Não existe uma política de privacidade disponível no site - apenas um local onde o utilizador pode “sair da base de dados”.
Fiz então o meu pedido para o e-mail indicado na política de privacidade disponível do Facebook da empresa. Não só não recebi resposta, como a política ficou entretanto indisponível.
Na política de privacidade agora indisponível, a empresa dizia recolher dados pessoais de clientes “através de concursos e passatempos”.
No capítulo “com quem são partilhados os seus dados”, a empresa assumia que podia partilhá-los com dezenas de entidades: com os seus “patrocinadores”, uma lista de 78 empresas; com entidades do grupo em que a Content Ignition está inserida - o grupo português ActualSales; com autoridades, empresas de recrutamento e seleção e ainda com subcontratantes.
Ainda com dúvidas sobre como as empresas chegam ao seu número de telefone? Cuidado com as letras pequenas nos passatempos em que participa. E se quiser saber que dados têm seus, exerça os seus direitos.
Nota metodológica
Os dados aqui analisados resultam de uma série de 72 pedidos de acesso a dados feitos pela autora do artigo, desde abril a novembro de 2021, na qualidade de titular dos dados - sem se apresentar como jornalista - com o objetivo de avaliar como as entidades dão resposta a este exercício de direitos fundamentais.
A amostra engloba 72 entidades, das quais 64 privadas e oito públicas.
Em alguns casos, em que a autora não é a titular do contrato do serviço que usa, o pedido foi feito por outra pessoa.
A análise dos dados fornecidos pela Google, através do Google Takeout, foi feita com recurso a linguagem R, com código criado pelo programador Saúl Buentello. O código completo está disponível aqui.